Fitting a mass model
Since the sound crossing time in a galaxy cluster is much smaller than the cluster formation time, the gas in these systems is roughly in equilibrium between the gravitational force and the thermal pressure gradient. Therefore, the hydrostatic equilibrium equation can be used to get an estimate of the total gravitating mass profile,
If a parametric model \(M(<r)= f(r|\theta)\) respective to a set of parameters \(\theta\) can be defined for the total mass, the hydrostatic equilibrium equation and the gas density profile can be integrated to predict the 3D pressure profile,
The model pressure can then be projected and convolved with instrumental effects to predict the X-ray spectroscopic temperature profile and the SZ pressure profile.
This tutorial explains how to use hydromass and pyproffit to fit a mass model to X-ray data from a galaxy cluster under the assumption that the gas is in hydrostatic equilibrium. The chosen example is applied to XMM-Newton observations of the massive galaxy cluster MACS 0451 at z=0.54, which were published in Tam et al. (2020) and was found to be in excellent agreement with the gravitational lensing data.
The provided test data include a soft-band (0.7-1.2 keV) image of the cluster with an exposure and a non X-ray background map, as well as a spectroscopic temperature profile extracted by fitting an APEC model to XMM-Newton spectra extracted in concentric annuli. We refer to Ghirardini et al. (2019) for details on the data analysis procedure.
Let’s start by loading the packages…
[1]:
import numpy as np
import pyproffit
import hydromass
import matplotlib.pyplot as plt
We start by loading the images in pyproffit using the pyproffit.Data class. We refer to the pyproffit documentation for more details.
Here imglink=‘epic-obj-im-700-1200.fits’ is the link to the image file (count map) to be loaded.
The option explink=’epic-exp-im-700-1200.fits’ allows the user to load an exposure map for vignetting correction. In case this option is left blank, a uniform exposure of 1s is assumed for the observation.
The option bkglink=’epic-back-oot-sky-700-1200.fits’ allows to load an external background map, which will be used when extracting surface brightness profiles.
The images are then loaded into the Data structure
[2]:
datv = pyproffit.Data(imglink='../../test_data/epic-obj-im-700-1200.fits',
explink='../../test_data/epic-exp-im-700-1200.fits',
bkglink='../../test_data/comb-back-tot-sky-700-1200.fits')
# Filter out point sources by loading a DS9 region file
datv.region('../../test_data/src_mask.reg')
Excluded 41 sources
WARNING: FITSFixedWarning: RADECSYS= 'FK5 ' / World coord. system for this file
the RADECSYS keyword is deprecated, use RADESYSa. [astropy.wcs.wcs]
WARNING: FITSFixedWarning: 'datfix' made the change 'Set MJD-OBS to 53264.994907 from DATE-OBS.
Set MJD-END to 53265.507373 from DATE-END'. [astropy.wcs.wcs]
Profile extraction
Now we define a Profile object and fit the background with a constant. We refer to the pyproffit documentation for the details of the surface brightness profile extraction
[3]:
prof = pyproffit.Profile(datv, center_choice='peak', binsize=5, maxrad=15.)
prof.SBprofile()
Determining X-ray peak
Coordinates of surface-brightness peak: 428.0 416.0
Corresponding FK5 coordinates: 73.5456401039549 -3.0148262711063816
The cluster being at relatively high redshift, it is well contained within the XMM-Newton field of view. Therefore we can fit the data at large radii with a constant brightness model to determine the local sky background emission. Here we assume that the brightness beyond 7 arcmin from the cluster center is completely dominated by the sky background…
[4]:
mod = pyproffit.Model(pyproffit.Const)
fitter = pyproffit.Fitter(model=mod, profile=prof, bkg=-3.8, fitlow=7., fithigh=15.)
fitter.Migrad()
┌─────────────────────────────────────────────────────────────────────────┐
│ Migrad │
├──────────────────────────────────┬──────────────────────────────────────┤
│ FCN = 122.6 │ Nfcn = 30 │
│ EDM = 9.85e-11 (Goal: 0.0002) │ │
├──────────────────────────────────┼──────────────────────────────────────┤
│ Valid Minimum │ No Parameters at limit │
├──────────────────────────────────┼──────────────────────────────────────┤
│ Below EDM threshold (goal x 10) │ Below call limit │
├───────────────┬──────────────────┼───────────┬─────────────┬────────────┤
│ Covariance │ Hesse ok │ Accurate │ Pos. def. │ Not forced │
└───────────────┴──────────────────┴───────────┴─────────────┴────────────┘
┌───┬──────┬───────────┬───────────┬────────────┬────────────┬─────────┬─────────┬───────┐
│ │ Name │ Value │ Hesse Err │ Minos Err- │ Minos Err+ │ Limit- │ Limit+ │ Fixed │
├───┼──────┼───────────┼───────────┼────────────┼────────────┼─────────┼─────────┼───────┤
│ 0 │ bkg │ -3.604 │ 0.009 │ │ │ │ │ │
└───┴──────┴───────────┴───────────┴────────────┴────────────┴─────────┴─────────┴───────┘
┌─────┬──────────┐
│ │ bkg │
├─────┼──────────┤
│ bkg │ 7.84e-05 │
└─────┴──────────┘
Best fit chi-squared: 122.556 for 180 bins and 95 d.o.f
Reduced chi-squared: 1.29006
[5]:
prof.Plot(model=mod, axes=[7., 15., 1e-4, 1e-3])
<Figure size 432x288 with 0 Axes>
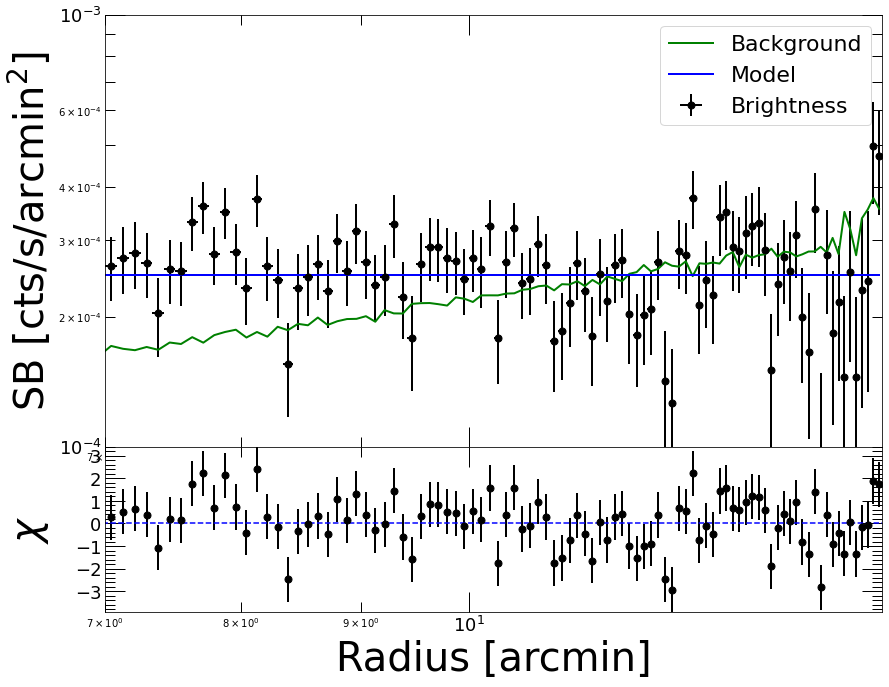
We can see that the background beyond 7 arcmin is reasonably flat and thus can be reliably subtracted to determine the source profile.
Now we extract a new profile with logarithmic binning and subtract the background…
[6]:
p2 = pyproffit.Profile(datv, center_choice='peak', binsize=5, maxrad=4.5, binning='log')
p2.SBprofile()
p2.Backsub(fitter)
p2.Plot()
Determining X-ray peak
Coordinates of surface-brightness peak: 428.0 416.0
Corresponding FK5 coordinates: 73.5456401039549 -3.0148262711063816
<Figure size 432x288 with 0 Axes>
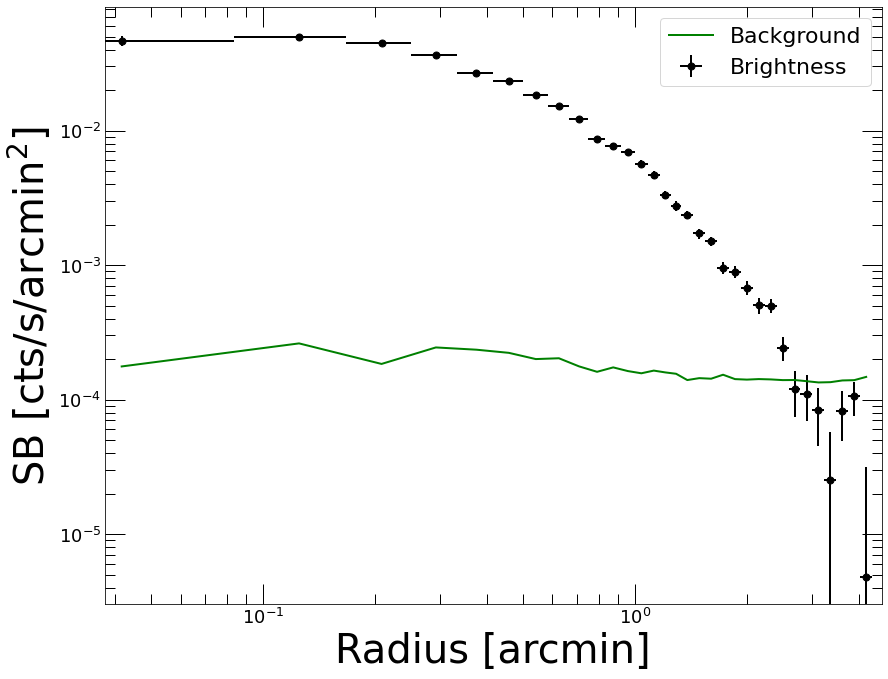
Modeling the PSF
To model the PSF we can either supply a function or an image. The function should take an array of radii (in arcmin) and return the 1D PSF profile. Here the provided function gives a good description of the on-axis XMM-Newton PSF. Again we refer to the pyproffit documentation for more details on this part.
[7]:
def fking(x):
r0=0.0883981
alpha=1.58918
return np.power(1.+(x/r0)**2,-alpha)
p2.PSF(psffunc=fking)
The final profile and the PSF mixing matrix can now be saved into an output FITS file to be reloaded later and avoid re-extracting the profiles,
[8]:
p2.Save(outfile='mhyd/test_sb_profile.fits')
WARNING: VerifyWarning: Keyword name 'ROT_ANGLE' is greater than 8 characters or contains characters not allowed by the FITS standard; a HIERARCH card will be created. [astropy.io.fits.card]
WARNING: VerifyWarning: Keyword name 'ELL_RATIO' is greater than 8 characters or contains characters not allowed by the FITS standard; a HIERARCH card will be created. [astropy.io.fits.card]
WARNING: VerifyWarning: Card is too long, comment will be truncated. [astropy.io.fits.card]
Defining the model
Now that we have extracted the surface brightness profile we can define the mass model and load the appropriate data into it. This is done through the hydromass.Mhyd class.
X-ray spectral fitting results (temperature, normalization, and metal abundance) can be loaded using the hydromass.SpecData class. The data can be passed either in the form a FITS table file including the definition of the radial binning and the spectral results, or directly as numpy arrays. An SZ pressure profile and its covariance matrix can be loaded in a similar way using the hydromass.SZData class.
Here we load the spectral results FITS file provided as part of the test data. We also compute a PSF mixing matrix that is appropriate for the radial binning of the spectral results, using the same PSF model as for the surface brightness.
[9]:
z_m0451 = 0.5398 # Source redshift
spec_data = hydromass.SpecData(redshift=z_m0451,
spec_data='../../test_data/spectral_results_MACS0451.fits')
spec_data.PSF(pixsize=2.5/60.,
psffunc=fking)
Reading spectral data from file ../../test_data/spectral_results_MACS0451.fits
The constructor of the Mhyd class requires the following input:
profile=prof: a pyproffit.Profile object including the SB profile
spec_data=file: a hydromass.SpecData object containing the X-ray spectroscopic temperature profile
sz_data=file: a hydromass.SZData containing an SZ pressure profile and its covariance matrix
redshift=z: source redshift
cosmo=cosmo: adopted cosmology in astropy.cosmology format. If cosmo=None (default), use Planck15.
directory=dir: name of output file directory. If directory=None (default), a subdirectory with name ‘mhyd’ will be created.
f_abund=’angr’: abundance table definition for calculation of electron to proton ratio and mean molecular weight. Default=’angr’, also available are ‘aspl’ and ‘grsa’
Note that either spec_data or sz_data or both can be specified. In case both a spectroscopic temperature profile and an SZ pressure profile are provided the two datasets or fitted jointly.
[10]:
tmhyd = hydromass.Mhyd(sbprofile=p2,
spec_data=spec_data,
redshift=z_m0451)
No output directory name provided, will output to subdirectory "mhyd"
No cosmology provided, will default to Planck15
Luminosity distance to the source: 3199.29 Mpc
At the redshift of the source 1 arcmin is 392.511 kpc
Now let’s define a mass model. This is done with the hydromass.Model class, which accepts the following option:
massmod=NFW: mass model definition. Available models are ‘NFW’, ‘EIN2’, ‘EIN3’, ‘BUR’, ‘ISO’, and ‘HER’.
delta=val: overdensity at which R_delta and c_delta are defined in the model (default=200).
start=start: an array containing the mean values of the Gaussian priors on the parameters. If None, default values for each model will be set.
sd=sd: an array contianing the sigma of the Gaussian priors on the parameters. If None, default values for each model will be set.
limits=limits: a 2D-array containing upper and lower limits for the parameter values. If None, default values for each model will be set.
fixed=fix: a boolean array describing if a parameter is fixed or fitted. For instance, for a model with 2 parameters for which we want to fix the first one, we pass fix=[True, False]. If fix=True, the value given in start is used. By default all parameters are fitted.
To begin with, we fit an NFW model with broad Normal priors on concentration and overdensity radius. We also set the acceptable ranges of the model parameters, which here are very broad.
[11]:
start = [4., 2000.] # Central values of the Normal prior on concentration and overdensity radius (in kpc)
sd = [3., 1000.] # Standard deviation of the Normal prior
limits = np.array([[0.5, 10.],[300., 4000.]]) # Lower and upper boundaries on the model parameters
model = hydromass.Model(massmod='NFW',
start=start,
sd=sd,
limits=limits)
Here we have set the following priors
To determine the conversion between detector count rate and intrinsic emission measure, we need to simulate an absorbed APEC model spectrum with known emission measure and fold it through the response of the instrument. This is done through the hydromass.Mhyd.emissivity, which uses a model spectrum to relate the normalization of the APEC model with the expected source count rate. An XSPEC command under the hood, so XSPEC must be accessible. If no temperature is provided, the mean spectral temperature of the loaded spectroscopic temperature profile is used.
Since we are observing in a soft energy band (0.7-1.2 keV), the emissivity is a weak function of temperature and can be assumed to be constant across the radial range given the average cluster temperature of 8 keV. This is not necessarily the case for galaxy groups, for which the emissivity depends substantially on temperature and metallicity.
[12]:
nh_m0451 = 0.0454 # Galactic NH
rsp = '/Users/deckert/Documents/Work/devel/hydromass/test_data/m1.rsp' # on-axis response file
tmhyd.emissivity(nh=nh_m0451, rmf=rsp, elow=0.7, ehigh=1.2)
print('Conversion between count rate and emission measure: ', tmhyd.ccf)
Mean cluster temperature: 8.161195 keV
XSPEC version: 12.12.0
Build Date/Time: Fri Jan 14 18:24:26 2022
XSPEC12>cosmo 67.74 0 0.69101
XSPEC12>abund angr
Solar Abundance Vector set to angr: Anders E. & Grevesse N. Geochimica et Cosmochimica Acta 53, 197 (1989)
XSPEC12>model phabs(apec)
Input parameter value, delta, min, bot, top, and max values for ...
1 0.001( 0.01) 0 0 100000 1e+06
1:phabs:nH>0.0454
1 0.01( 0.01) 0.008 0.008 64 64
2:apec:kT>8.16119
1 -0.001( 0.01) 0 0 5 5
3:apec:Abundanc>0.3
0 -0.01( 0.01) -0.999 -0.999 10 10
4:apec:Redshift>0.5398
1 0.01( 0.01) 0 0 1e+20 1e+24
5:apec:norm>1.0
Reading APEC data from 3.0.9
========================================================================
Model phabs<1>*apec<2> Source No.: 1 Active/Off
Model Model Component Parameter Unit Value
par comp
1 1 phabs nH 10^22 4.54000E-02 +/- 0.0
2 2 apec kT keV 8.16119 +/- 0.0
3 2 apec Abundanc 0.300000 frozen
4 2 apec Redshift 0.539800 frozen
5 2 apec norm 1.00000 +/- 0.0
________________________________________________________________________
XSPEC12>fakeit none
For fake spectrum #1 response file is needed: /Users/deckert/Documents/Work/devel/hydromass/test_data/m1.rsp
...and ancillary file:
Use counting statistics in creating fake data? (y):
Input optional fake file prefix:
Fake data file name (m1.fak):
10000, 1e time, correction norm, bkg exposure time (1.00000, 1.00000, 1.00000):
No background will be applied to fake spectrum #1
No ARF will be applied to fake spectrum #1 source #1
1 spectrum in use
Fit statistic : Chi-Squared 851.53 using 800 bins.
***Warning: Chi-square may not be valid due to bins with zero variance
in spectrum number: 1
Test statistic : Chi-Squared 851.53 using 800 bins.
***Warning: Chi-square may not be valid due to bins with zero variance
in spectrum number(s): 1
Null hypothesis probability of 8.81e-02 with 797 degrees of freedom
Current data and model not fit yet.
XSPEC12>ign **-0.70
47 channels (1-47) ignored in spectrum # 1
Fit statistic : Chi-Squared 799.19 using 753 bins.
***Warning: Chi-square may not be valid due to bins with zero variance
in spectrum number: 1
Test statistic : Chi-Squared 799.19 using 753 bins.
***Warning: Chi-square may not be valid due to bins with zero variance
in spectrum number(s): 1
Null hypothesis probability of 1.04e-01 with 750 degrees of freedom
Current data and model not fit yet.
XSPEC12>ign 1.20-**
720 channels (81-800) ignored in spectrum # 1
Fit statistic : Chi-Squared 32.64 using 33 bins.
Test statistic : Chi-Squared 32.64 using 33 bins.
Null hypothesis probability of 3.39e-01 with 30 degrees of freedom
Current data and model not fit yet.
XSPEC12>log sim.txt
Logging to file:sim.txt
XSPEC12>show rates
Spectral Data File: m1.fak
Assigned to Data Group 1 and Plot Group 1
Net count rate (cts/s) for Spectrum:1 2.125e+01 +/- 4.610e-02
Spectral data counts: 212515
Model predicted rate: 21.2197
XSPEC12>log none
Log file closed
logging switched off
XSPEC12>quit
XSPEC: quit
Conversion between count rate and emission measure: 21.25
Running the code
We are now ready to run the reconstruction. This is done using the run method of the hydromass.Mhyd class, which includes a large number of options:
model=model: hydromass.Model object containing the definition of the mass model.
nmcmc=1000: number of output samples from PyMC3/NUTS run (default=1000).
tune=500: number of PyMC3/NUTS tuning steps (default=500). Increasing the tune value leads to better convergence but slower runs.
nmore=5: fine grid definition for mass model calculation. The spec_data/sz_data grid will be split into 2*nmore bins inside which mass and pressure derivatives will be computed. Increasing nmore leads to greater precision in model pressure calculaton, but obviously slower runs.
p0_prior=p0_prior: array containing the mean and standard deviation of the Gaussian prior on P0. If None, the prior on P0 will be set automatically by fitting a gNFW profile.
dmonly=False: decide whether we want to fit the total mass or the DM mass only by subtracing the baryonic mass (default=False).
mstar=mstar: in case dmonly=True, input a stellar mass profile as a 2D array including R (in kpc) and M_star (in Msun) in the two columns.
fit_bkg=False: choose whether we want to fit the background on-the-fly and the counts using Poisson statistics, or if we use directly a background-subtracted brightness profile (default option), in which case Gaussian statistics is used.
bkglim=bkglim: in case fit_bkg=True, set the maximum detection radius beyond which it is assumed that the source is negligible with respect to the background. If bkglim=None it will be assumed that the source is important everywhere.
back=back: in case fit_bkg=True, give an input value for the background and set a narrow Gaussian prior centered on this value. If back=None the input value will be estimated as the mean value at r>bkglim.
samplefile=file: name of output file to save the final PyMC3/NUTS samples.
Here we do a quick test run with standard parameters and a small number of tuning steps. The pressure at the outer boundary (\(P_0\)) is estimated on-the-fly by fitting a model to the pressure profile and extrapolating it to the outer boundary.
[13]:
tmhyd.run(model=model, nmcmc=100, tune=100)
Single conversion factor provided, we will assume it is constant throughout the radial range
Estimated value of P0: 0.000546325
coefs -187.90419872441586
cdelta_interval__ -1.0833801859728536
rdelta_interval__ -0.9384616845706304
logp0_interval__ -1.2303705795943691
Running HMC...
Only 100 samples in chain.
Auto-assigning NUTS sampler...
Initializing NUTS using advi...
Convergence achieved at 17700
Interrupted at 17,699 [8%]: Average Loss = 235
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [logp0, rdelta, cdelta, coefs]
Sampling 4 chains for 100 tune and 100 draw iterations (400 + 400 draws total) took 22 seconds.
The chain reached the maximum tree depth. Increase max_treedepth, increase target_accept or reparameterize.
The chain reached the maximum tree depth. Increase max_treedepth, increase target_accept or reparameterize.
The chain reached the maximum tree depth. Increase max_treedepth, increase target_accept or reparameterize.
There were 17 divergences after tuning. Increase `target_accept` or reparameterize.
The chain reached the maximum tree depth. Increase max_treedepth, increase target_accept or reparameterize.
The rhat statistic is larger than 1.05 for some parameters. This indicates slight problems during sampling.
The number of effective samples is smaller than 10% for some parameters.
Done.
Total computing time is: 0.6762712677319844 minutes
/Users/deckert/opt/anaconda3/lib/python3.9/site-packages/arviz/stats/stats.py:1458: UserWarning: For one or more samples the posterior variance of the log predictive densities exceeds 0.4. This could be indication of WAIC starting to fail.
See http://arxiv.org/abs/1507.04544 for details
warnings.warn(
/Users/deckert/opt/anaconda3/lib/python3.9/site-packages/arviz/stats/stats.py:694: UserWarning: Estimated shape parameter of Pareto distribution is greater than 0.7 for one or more samples. You should consider using a more robust model, this is because importance sampling is less likely to work well if the marginal posterior and LOO posterior are very different. This is more likely to happen with a non-robust model and highly influential observations.
warnings.warn(
Visualizing the results
The PyMC3 optimization run returns a trace object which can be visualized using the Arviz library. Here we use Arviz to check out the resulting chains and verify convergence
[14]:
import arviz as az
az.plot_trace(tmhyd.trace, var_names=['rdelta', 'cdelta', 'logp0'])
[14]:
array([[<AxesSubplot:title={'center':'rdelta'}>,
<AxesSubplot:title={'center':'rdelta'}>],
[<AxesSubplot:title={'center':'cdelta'}>,
<AxesSubplot:title={'center':'cdelta'}>],
[<AxesSubplot:title={'center':'logp0'}>,
<AxesSubplot:title={'center':'logp0'}>]], dtype=object)
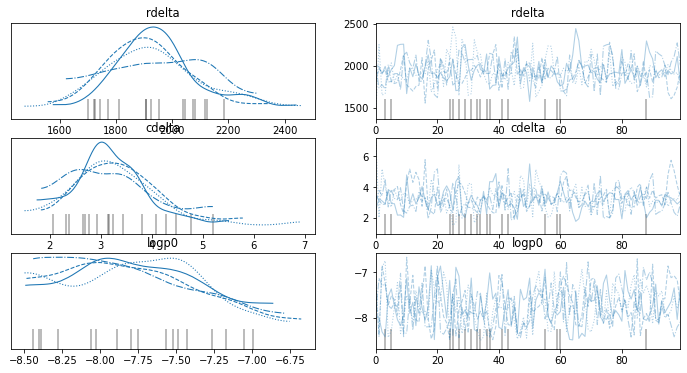
Clearly the four individual chains return very similar results and the chains look well converged, even with just 100 steps and 100 tuning steps. We can also have a look at the posterior distributions for the parameters of interest
[15]:
az.plot_posterior(tmhyd.trace, var_names=['rdelta', 'cdelta'])
[15]:
array([<AxesSubplot:title={'center':'rdelta'}>,
<AxesSubplot:title={'center':'cdelta'}>], dtype=object)

To check the quality of the fit, hydromass runs posterior predictive checks, i.e. it generates random datasets from the model including the expected statistical uncertainties. The generated values can then be compared to the data. The posterior predictive samples can be accessed through the Mhyd.ppc_sb and Mhyd.ppc_kt attributes of the Mhyd class. In the following example we compare the posterior predictive surface brightness distribution to the data to determine whether the model does an appropriate job at describing the data
[16]:
plt.clf()
plt.style.use('MyStyle')
fig = plt.figure()
ax = fig.add_subplot()
plt.yscale('log')
plt.xscale('log')
plt.xlabel('Radius [arcmin]', fontsize=28)
plt.ylabel('$S_{X}$ [cts/s/arcmin$^2$]', fontsize=28)
plt.plot(p2.bins, tmhyd.sb, color='blue')
plt.fill_between(p2.bins, tmhyd.sb_lo, tmhyd.sb_hi, color='blue', alpha=0.5)
plt.errorbar(p2.bins, p2.profile, xerr=p2.ebins, yerr=p2.eprof, fmt='o', color='red')
plt.plot(p2.bins, np.median(tmhyd.ppc_sb['sb'], axis=0), color='black')
az.plot_hdi(
p2.bins,
tmhyd.ppc_sb['sb'],
ax=ax,
hdi_prob=.68,
)
/Users/deckert/opt/anaconda3/lib/python3.9/site-packages/arviz/plots/hdiplot.py:157: FutureWarning: hdi currently interprets 2d data as (draw, shape) but this will change in a future release to (chain, draw) for coherence with other functions
hdi_data = hdi(y, hdi_prob=hdi_prob, circular=circular, multimodal=False, **hdi_kwargs)
[16]:
<AxesSubplot:xlabel='Radius [arcmin]', ylabel='$S_{X}$ [cts/s/arcmin$^2$]'>
<Figure size 432x288 with 0 Axes>
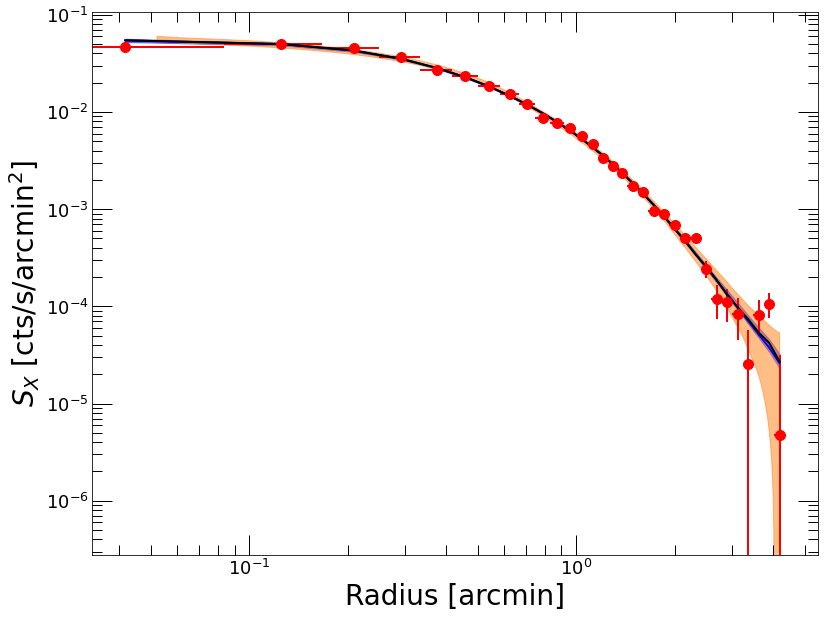
Here the blue shaded area shows the best-fit model and its corresponding 1-sigma range, whereas the orange area represents the 68% confidence region of the generated posterior predictive samples. Clearly the model provides a very good representation of the data.
We can now do the same thing with the temperature profile…
[17]:
plt.clf()
fig = plt.figure()
ax = fig.add_subplot()
plt.xlabel('Radius [arcmin]')
plt.ylabel('$T_{X}$ [keV]')
plt.errorbar(tmhyd.spec_data.rref_x_am,tmhyd.spec_data.temp_x,yerr=np.array([tmhyd.spec_data.templ,tmhyd.spec_data.temph]),fmt='*',color='red', label='Data')
plt.plot(tmhyd.spec_data.rref_x_am,tmhyd.ktmod,color='blue', label='Model $T_{spec}$')
plt.fill_between(tmhyd.spec_data.rref_x_am, tmhyd.ktmod_lo, tmhyd.ktmod_hi, color='blue', alpha=0.3)
plt.plot(tmhyd.spec_data.rref_x_am,tmhyd.kt3d,color='green', label='Model $T_{3D}$')
plt.plot(tmhyd.spec_data.rref_x_am, np.median(tmhyd.ppc_kt['kt'], axis=0), color='black')
az.plot_hdi(
tmhyd.spec_data.rref_x_am,
tmhyd.ppc_kt['kt'],
ax=ax,
hdi_prob=.68
)
plt.legend(fontsize=22)
/Users/deckert/opt/anaconda3/lib/python3.9/site-packages/arviz/plots/hdiplot.py:157: FutureWarning: hdi currently interprets 2d data as (draw, shape) but this will change in a future release to (chain, draw) for coherence with other functions
hdi_data = hdi(y, hdi_prob=hdi_prob, circular=circular, multimodal=False, **hdi_kwargs)
[17]:
<matplotlib.legend.Legend at 0x7f9c720687f0>
<Figure size 936x720 with 0 Axes>
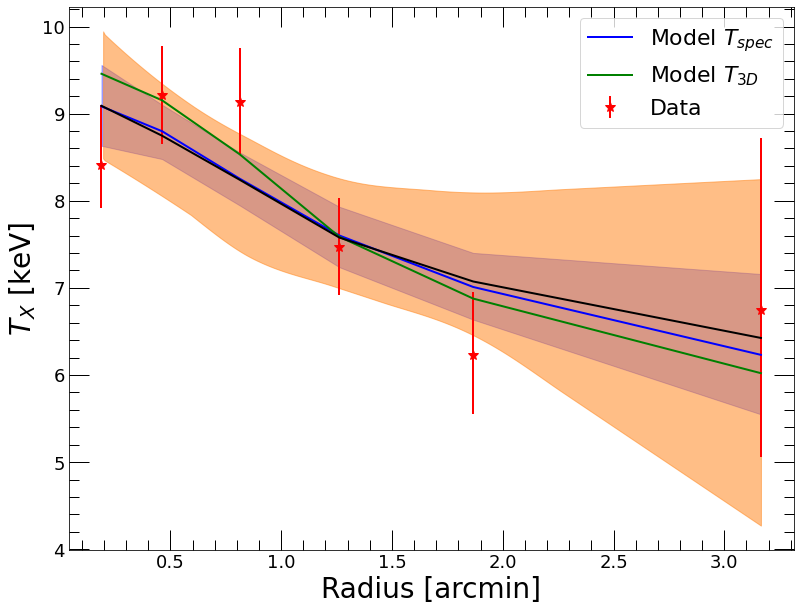
Again the model seems to provide an accurate representation of the data, as all the data points are included within the orange range. Here we have plotted both the fitted projected spectroscopic-like temperatures in blue and the corresponding 3D temperatures in green.
Finally we can save the resulting samples to an output FITS file using the hydromass.Mhyd.SaveModel method. The posterior parameter samples of the mass model and of the gas density model are saved and can be reloaded later on using the hydromass.ReloadModel function.
[18]:
tmhyd.SaveModel(model, outfile='mhyd/test_save.fits')
WARNING: VerifyWarning: Keyword name 'LOWcdelta' is greater than 8 characters or contains characters not allowed by the FITS standard; a HIERARCH card will be created. [astropy.io.fits.card]
WARNING: VerifyWarning: Keyword name 'LOWrdelta' is greater than 8 characters or contains characters not allowed by the FITS standard; a HIERARCH card will be created. [astropy.io.fits.card]
Computing overdensity radii and masses
hydromass allows the user to compute the radius within which the average density is equal to any user-defined overdensity from the fitted mass model. Namely, for each parameter and a given overdensity \(\Delta\) the code searches for the radius within which
with \(\rho_c\) the critical density of the Universe at the redshift of the system. The hydromass.calc_rdelta_mdelta numerically computes the posterior distributions of \(R_\Delta\) and \(M_\Delta=M(<R_\Delta)\). In the following we showcase the use of this function for \(\Delta=500\)
[19]:
res_r500, fig = hydromass.calc_rdelta_mdelta(500, tmhyd, model, plot=True)
<Figure size 936x720 with 0 Axes>
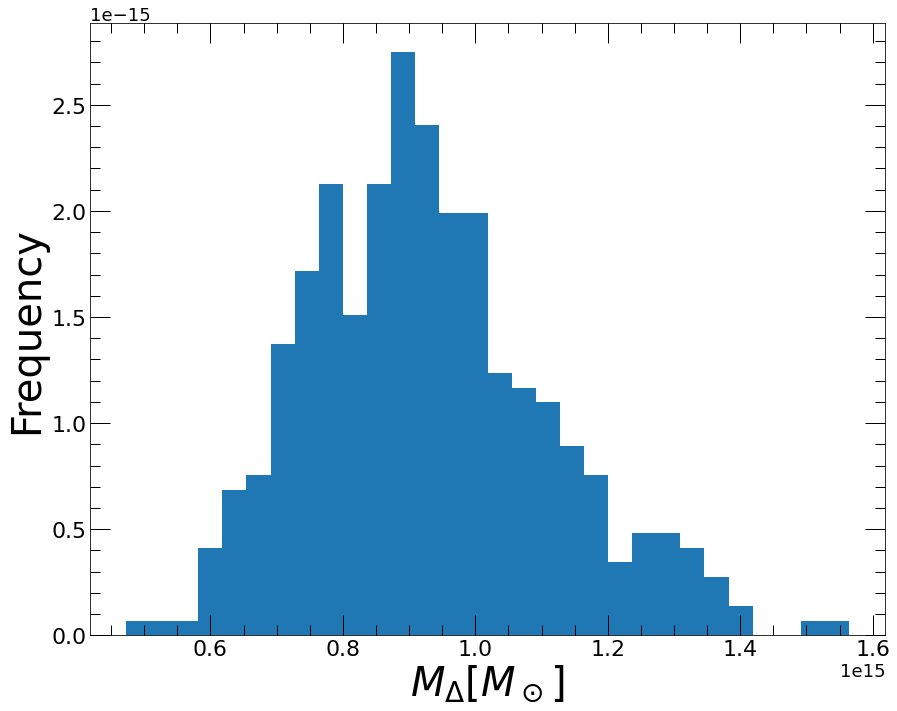
The output of the tool is a dictionary containing the median and 1-sigma error envelope of the overdensity radius, enclosed mass, gas mass, and gas fraction
[20]:
res_r500
[20]:
{'R_DELTA': 1232.9910674475118,
'R_DELTA_LO': 1157.723867339469,
'R_DELTA_HI': 1319.885040080051,
'M_DELTA': 909576034021675.5,
'M_DELTA_LO': 752964668916140.1,
'M_DELTA_HI': 1115754822457740.8,
'MGAS_DELTA': 125096386365429.19,
'MGAS_DELTA_LO': 117992291349397.7,
'MGAS_DELTA_HI': 131245245662375.42,
'FGAS_DELTA': 0.13787990881204581,
'FGAS_DELTA_LO': 0.11748226889506014,
'FGAS_DELTA_HI': 0.1580835501934931}
The hydromass.write_all_mdelta tool can be used to extract a diagnostic file including the best-fit overdensity radii and enclosed masses for \(\Delta\)=2500, 1000, 500, and 200. By default the results will be stored into a file entitled MODEL.jou under the output directory, with MODEL the name of the chosen mass model (here NFW).
[21]:
hydromass.write_all_mdelta(tmhyd, model, rmin=100., rmax=4000.)
Output mass profiles
The handy function hydromass.mass_from_samples allows the user to extract posterior mass profiles within any user-defined radial range. The tool also extracts the cumulative gas mass profile and the corresponding hot gas fraction as a function of radius. The output profiles can be easily plotted from the data and saved into output files.
[22]:
res_mass, fig = hydromass.mass_from_samples(Mhyd=tmhyd,
model=model,
plot=True)
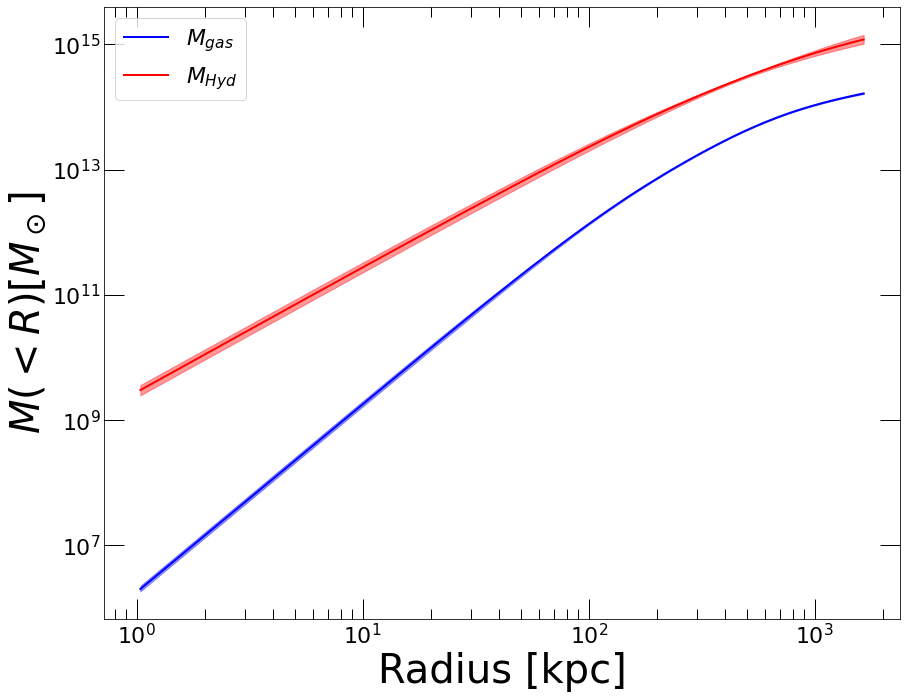
The output is a dictionary including the resulting mass profiles
[23]:
res_mass.keys()
[23]:
dict_keys(['R_IN', 'R_OUT', 'R_REF', 'MASS', 'MASS_LO', 'MASS_HI', 'M_DM', 'M_DM_LO', 'M_DM_HI', 'MGAS', 'MGAS_LO', 'MGAS_HI', 'FGAS', 'FGAS_LO', 'FGAS_HI', 'M_STAR'])
We can also have a look at the output gas fraction profile, defined as the ratio of cumulative gas mass to cumulative hydrostatic mass
[24]:
plt.clf()
fig = plt.figure()
ax= fig.add_subplot()
plt.xscale('log')
plt.xlabel('Radius [kpc]', fontsize=28)
plt.ylabel('$f_{gas}$', fontsize=28)
plt.plot(res_mass['R_OUT'], res_mass['FGAS'], color='blue', label='NFW $f_{gas}$')
plt.fill_between(res_mass['R_OUT'], res_mass['FGAS_LO'], res_mass['FGAS_HI'], color='blue', alpha=0.4)
ylim = ax.get_ylim()
plt.plot(res_mass['R_OUT'], 0.156*np.ones(len(res_mass['R_OUT'])), '--', color='black', label='$\Omega_b/\Omega_m$')
plt.plot([res_r500['R_DELTA'], res_r500['R_DELTA']], ylim, ':', color='red', label='$R_{500}$')
plt.legend(fontsize=22)
[24]:
<matplotlib.legend.Legend at 0x7f9c90d4f2e0>
<Figure size 936x720 with 0 Axes>
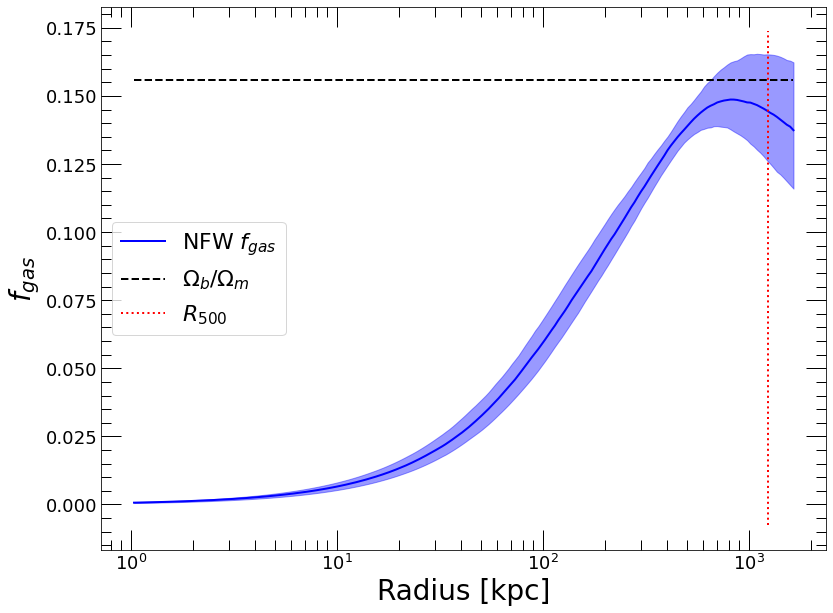
The hydrostatic gas fraction converges to a value that is very close to the cosmic baryon fraction at \(R_{500}\). This is a good indication that the reconstruction is accurate.
We can now save the output profiles into an output FITS file through the hydromass.SaveProfiles tool,
[25]:
hydromass.SaveProfiles(profiles=res_mass,
outfile='mhyd/NFW_mass_profile.fits',
extname='MASS PROFILE')